

Las plataformas de Oracle deberán asegurarse constantemente de un alto grado de confiabilidad, ya que se deberá presentar la información de precios correcta; de lo contrario, habrá pérdidas de dinero para los clientes intermedios. Esto es tanto más urgente cuanto más ha crecido la plataforma, se necesita para garantizar la exactitud de grandes cantidades de información, incluso una menor probabilidad de falla puede resultar inaceptable.
 cryptoshitcompra.com/wp-content/uploads/2022/04/¿Como-realiza-Pyth-Network-el-trabajo-para-medir-y-realizar.jpg» alt=»» width=»1400″ height=»787″/>
cryptoshitcompra.com/wp-content/uploads/2022/04/¿Como-realiza-Pyth-Network-el-trabajo-para-medir-y-realizar.jpg» alt=»» width=»1400″ height=»787″/>El mercado generalmente asume que todos los oráculos son iguales: todas y cada una de las fuentes de precios son excelentes y siempre presentarán las tarifas más correctas. La bonita idea de “oráculo” tiene la connotación de un soberano que habla constantemente de la realidad y no puede equivocarse. Sin embargo, esta percepción no es siempre apropiada. Es difícil establecer una técnica extremadamente respetable. Incluso los grandes proveedores de programas de software se ven obligados a dejar de ofrecer servicios, y los participantes estándar del mercado de dinero tienen que hacer el trabajo difícil para limpiar las fuentes de datos inexactas. Por lo tanto, la confiabilidad es importante y realmente crítica en una técnica de oráculo única.
En Pyth, Pyth se enfoca en una confiabilidad 3x. Pyth tiene un programa de copia de seguridad en el lugar si Oracle falla. En papel blanco, Pyth ha propuesto un mecanismo para este objetivo. La línea inicial de defensa de Pyth es establecer mecanismos y ensamblar fuentes de información ciertamente de alta calidad.
Como aspecto de esta publicación, a Pyth le gustaría dar una imagen más clara de cómo luchan por la confiabilidad de sus fuentes de información de precios. Pyth se propuso modelar de forma probabilística, cuantitativa y optimizar para lograr una confianza en sí mismo óptima.
¿Qué es la confiabilidad?
La confiabilidad es breve para la disponibilidad (disponibilidad) y la precisión:
- La disponibilidad es el porcentaje de tiempo que Oracle publica el costo.
- La precisión es el porcentaje de instancias en las que el costo del oráculo coincide con el costo general del mercado.
La información deberá presentarse de forma rápida y precisa. La precisión es importante: publicar un solo costo incorrecto puede provocar liquidaciones y pérdidas. Por lo tanto, debe asegurarse de que la probabilidad de publicar un costo incorrecto sea bastante menor. Sin embargo, incluso la disponibilidad limitada es perjudicial, ya que los retrasos pueden provocar pérdidas para los clientes.
Para cuantificar la confiabilidad, Pyth tendrá que cuantificar la usabilidad y la precisión. Para hacer esto, sumerjámonos en la siguiente área.
Modelo básico para la confiabilidad del avance de costos
Pyth agrega revisiones de varios editores diferentes para crear un valor agregado único, que incluso si algunos editores están fuera de línea o dan precios engañosos, no afectarán el valor siguiente entre sí. El feed de tarifas siempre estará disponible mientras al menos tres editores estén en línea.
Si se supone que los editores de datos son independientes, Pyth puede determinar rápidamente la probabilidad de que el valor compuesto sea incorrecto. Para ilustrarlo, considera un feed de precios de tres editores, en el que casi todos los editores tienen una tarifa de disponibilidad del 99 % y una tarifa de precisión del 99,9 %. Los tres editores deben estar en línea para agregar, la probabilidad de que esto suceda es:
 png» alt=»» width=»244″ height=»25″/>
png» alt=»» width=»244″ height=»25″/>
Como resultado, la tarifa fuera de línea es de 2,97%. Si el feed está en Internet, al menos dos de cada tres editores sin duda darán el precio correcto. Podemos determinar la probabilidad de esta ocasión de la siguiente manera:
 png» alt=»» width=»546″ height=»89″/>
png» alt=»» width=»546″ height=»89″/>
Por lo tanto, la tarifa de información de error es .0039%.
Riesgo de errores vinculados
Una dificultad con este examen es que los editores pueden cometer errores garrafales. Un examen tan sencillo ignora este problema, lo que nos hace sobrestimar la confiabilidad de una alimentación. Para ilustrar, supongamos que introducimos algunas dependencias complicadas adicionales en el modelo sin complicaciones anterior. Vincule los dos editores iniciales para que su disponibilidad y precisión sean iguales (por ejemplo, están trabajando en la misma infraestructura y usan el mismo algoritmo para publicar cargos). ). Así que podemos determinar la probabilidad de que la población en Internet valga de la siguiente manera:
![]()
Esto indica que la tarifa fuera de línea es del 1,99 %. La probabilidad de que el valor compuesto en línea y exacto llegue a ser:

Esto implica un cargo por error de .098%. El examen sin complicaciones subestima sustancialmente la probabilidad de falla de la alimentación de costos integral.
Relación entre los editores de información
A Pyth le gustaría modelar la confiabilidad de la fuente de costos de una manera que calcule con precisión la correlación entre los editores. Además, a Pyth le gustaría dar estimaciones agregadas por medio de los dos cargos agregados y los intervalos de autoconfianza.
Una forma de establecer este modelo es significar directamente el enfoque de apariencia física de costo en la cadena. Los editores revisan las fuentes de costos de intercambios distintivos, los agregan en una estimación de costos y luego los envían a la cadena. El enfoque completo se completa en un plan de software que lee constantemente la información y envía actualizaciones. Hay muchas fases en este enfoque en las que pueden surgir problemas:
- Es posible que la fuente de costos subyacente no sea correcta. Este error puede influir en que todos los editores lean el feed de costos incorrecto al mismo tiempo.
- El programa de software para procesar feeds puede cometer errores y hacer que se cite incorrectamente.
- La infraestructura del editor falló, lo que les impidió enviar transacciones. En la situación más fácil, el plan de software de un editor puede colapsar o su infraestructura de almacenamiento deja de funcionar.
- Dichos errores de confirmación de transacciones también pueden ocurrir debido a la congestión de la red Solana, interrupciones del nodo RPC o dificultades con el host del editor. Tenga en cuenta que muchos de estos modos de error afectarán a muchos editores al mismo tiempo.
El objetivo de Pyth es estimar la probabilidad de que estos errores afecten el costo agregado y el intervalo de confianza en uno mismo. Cada uno de estos errores tiene una probabilidad específica de ocurrencia que Pyth puede estimar a partir de información histórica. Los cargos agregados y los intervalos de confianza en uno mismo son una combinación de muchos cargos de los editores, por lo que Pyth necesitaba una forma de combinar las probabilidades de fallas personales. Para ello, Pyth utiliza una red bayesiana, un instrumento que representa las distribuciones de probabilidad como una cantidad de distribuciones parciales de menor tamaño:
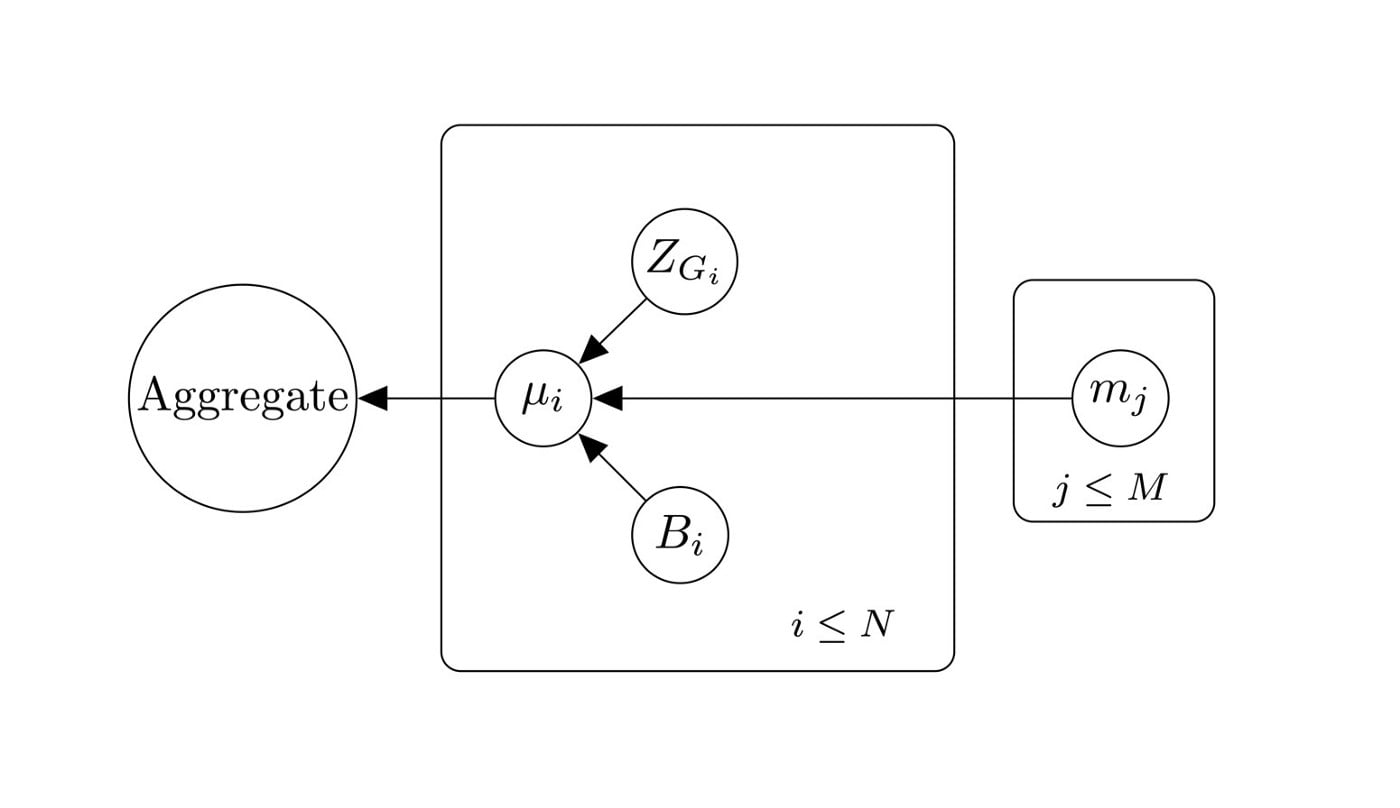
Bayes representa una distribución de probabilidad más que un conjunto de variables. Cada círculo en el diagrama anterior representa una variable, y los bordes significan las dependencias entre las variables. Cada variable puede obtener 1 de muchos valores, por ejemplo, el valor compuesto puede ser Preciso, INEXACTO o NO en la web. Bayes determina la probabilidad de casi todos estos valores. Echa un vistazo a estas notas para una aparición en Bayes.
Bayes asume que existe un conjunto de N editores de información y M intercambios. La red tiene numerosas variables para casi todos los editores e intercambios. Llamamos al editor de variables i e intercambiamos las variables j. La red codifica una distribución de probabilidad en las siguientes variables:
- mⱼ representa una alimentación del intercambio j. Esta variable tiene dos valores: Precisa o Precisa, indicando si el costo de cambio actual es adecuado o no.
- significa si el editor está encontrando errores en el programa de software. Esta variable tiene dos valores: BUG o NO_BUG. Cuando el valor de esta variable es BUG, el editor citará incorrectamente el costo en cadena.
- Z_Gᵢ significa que no importa si la infraestructura del editor i está en Internet o no. Esta variable tiene dos valores: En la web o SIN CONEXIÓN. Pyth ha agrupado a los editores para señalar el hecho de que muchos editores comparten la misma infraestructura. La variable Gᵢ representa el grupo al que pertenece el i-ésimo editor. Como resultado final, todos los editores del mismo grupo se desconectan entre sí.
- μᵢ representa el valor que el editor i envía en la cadena. Esta variable puede tener tres valores: Preciso, NO Preciso o SIN CONEXIÓN. Esta variable depende de los intercambios de los que el editor obtendrá el suministro de información (de la variable mⱼ), la posición de error del programa de software del editor (el borde de la variable Bᵢ) y la posición en línea del editor (de la variable mⱼ). Z_G). Por ejemplo, si la infraestructura del editor está fuera de línea (Z_Gᵢ = OFFLINE), el costo del editor será = OFFLINE.
- Agregado representa el costo agregado. Esta variable puede tener tres valores: Preciso, NO Preciso o SIN CONEXIÓN. Esta variable depende del costo de la editorial (de la variable μᵢ). Este valor se establece mediante la codificación de la lógica agregada del plan en cadena como una distribución de probabilidad. Específicamente, si esta variable está SIN CONEXIÓN excepto si tres o más editores citan una cotización. No sería honesto si más del 50% de los editores en línea estuvieran equivocados. De lo contrario, es preciso. Los umbrales porcentuales utilizados en esta distribución son propiedades de la lógica compuesta de Pyth.
Este modelo le permite a Pyth generar las probabilidades de los modos de falla enumerados anteriormente y luego combinar las probabilidades individuales para determinar si el valor compuesto es adecuado. Este enfoque utiliza un algoritmo identificado como creer en la propagación. La propagación de creencias es un método estudiado de manera efectiva para calcular de manera efectiva las probabilidades bayesianas. Para obtener información adicional sobre la difusión de la fe, consulte estas notas y video esto beneficioso.
Uso de Bayes para identificar la confiabilidad de la alimentación
Una situación de uso para Bayesian es estimar la confiabilidad de una fuente de costos de Pyth. Podemos identificar esta probabilidad estimando la probabilidad de casi todos los modos de sobrefalla basados principalmente en información histórica y luego combinándolos con Bayes.
Pyth utilizó una tienda de información…
Si quiere puede hacernos una donación por el trabajo que hacemos, lo apreciaremos mucho.
Direcciones de Billetera:
- BTC: 14xsuQRtT3Abek4zgDWZxJXs9VRdwxyPUS
- USDT: TQmV9FyrcpeaZMro3M1yeEHnNjv7xKZDNe
- BNB: 0x2fdb9034507b6d505d351a6f59d877040d0edb0f
- DOGE: D5SZesmFQGYVkE5trYYLF8hNPBgXgYcmrx
También puede seguirnos en nuestras Redes sociales para mantenerse al tanto de los últimos post de la web:
- Telegram
Disclaimer: En Cryptoshitcompra.com no nos hacemos responsables de ninguna inversión de ningún visitante, nosotros simplemente damos información sobre Tokens, juegos NFT y criptomonedas, no recomendamos inversiones