

Alors qu’un nombre croissant d’entreprises utilisent le Big Data en temps réel pour obtenir des informations et prendre des décisions basées sur les données, le besoin d’un outil résilient pour traiter ces données en temps réel augmente également.

Apache Kafka est un outil utilisé dans les systèmes Big Data en raison de sa capacité à gérer un débit élevé et le traitement en temps réel de grandes quantités de données.
Qu’est-ce qu’Apache Kafka
Apache Kafka est un logiciel open source qui permet de stocker et de traiter des flux de données sur une plateforme de streaming distribuée. Il fournit diverses interfaces pour écrire des données sur des clusters Kafka et lire, importer et exporter des données vers et depuis des systèmes tiers.

Apache Kafka a été initialement développé comme une file d’attente de messages LinkedIn. En tant que projet de l’Apache Software Foundation, le logiciel open source s’est développé en une plate-forme de streaming robuste avec un large éventail de fonctions.
Le système est basé sur une architecture distribuée centrée autour d’un cluster contenant plusieurs sujets, optimisé pour traiter de gros flux de données en temps réel comme le montre l’image ci-dessous :
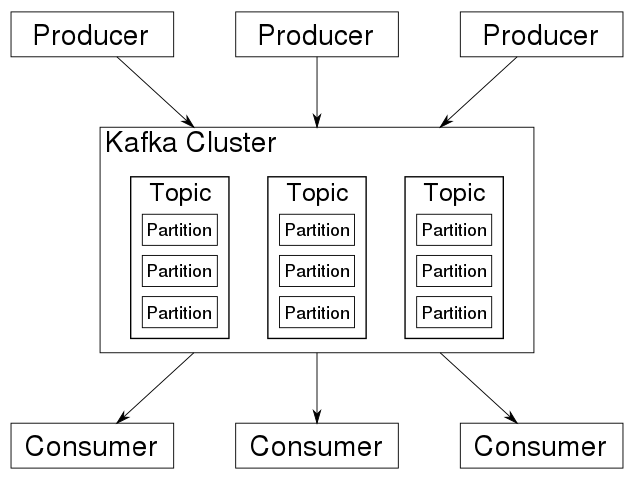
Avec l’aide de Kafka, les flux de données peuvent être stockés et traités. Cela rend Kafka adapté à de grandes quantités de données et d’applications dans l’environnement du Big Data.
Il est possible de charger des flux de données à partir de systèmes tiers ou de les exporter vers ces systèmes via les interfaces fournies. Le composant central du système est un commit distribué ou un journal des transactions.
Kafka : fonction de base
Kafka résout les problèmes qui surviennent lorsque les sources de données et les récepteurs de données sont connectés directement.
Par exemple, lorsque les systèmes sont connectés directement, il est impossible de mettre en mémoire tampon les données si le destinataire n’est pas disponible. De plus, un expéditeur peut surcharger le destinataire s’il envoie des données plus rapidement que le destinataire ne les accepte et ne les traite.
Kafka agit comme un système de messagerie entre l’expéditeur et le destinataire. Grâce à son journal des transactions distribué, le système peut stocker des données et les rendre disponibles avec une haute disponibilité. Les données peuvent être traitées à grande vitesse dès leur arrivée. Les données peuvent être agrégées en temps réel.
Architecture de Kafka
L’architecture de Kafka consiste en un réseau informatique en cluster. Dans ce réseau d’ordinateurs, les soi-disant courtiers stockent les messages avec un horodatage. Ces informations sont appelées rubriques. Les informations stockées sont répliquées et distribuées dans le cluster.
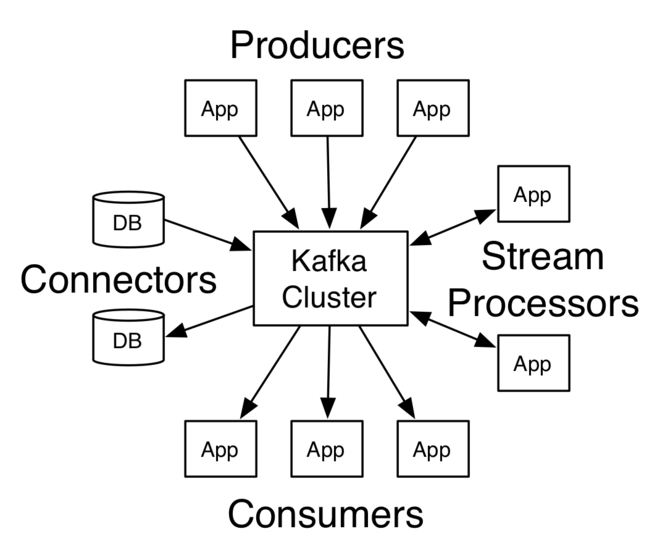
Les producteurs sont des applications qui écrivent des messages ou des données dans un cluster Kafka. Les consommateurs sont des applications qui lisent les données du cluster Kafka.
De plus, une bibliothèque Java appelée Kafka Streams lit les données du cluster, les traite et réécrit les résultats dans le cluster.
Kafka fait la distinction entre les « sujets normaux » et les « sujets compactés ». Les rubriques normales sont stockées pendant une certaine période et ne doivent pas dépasser une taille de stockage définie. Si la période de limite de stockage est dépassée, Kafka peut supprimer les anciens messages. Les sujets compactés ne sont soumis ni à une limite de temps ni à une limite d’espace de stockage.
 cryptoshitcompra.com/wp-content/uploads/2023/01/1675003050_854_Apache-Kafka-explique-en-5-minutes-ou-moins.png«/>
cryptoshitcompra.com/wp-content/uploads/2023/01/1675003050_854_Apache-Kafka-explique-en-5-minutes-ou-moins.png«/>
Un sujet est divisé en partitions. Le nombre de partitions est défini lors de la création du sujet et détermine la façon dont le sujet évolue. Les messages d’un sujet sont distribués aux partitions. Le décalage est par partition. Les partitions sont le mécanisme fondamental par lequel fonctionnent à la fois la mise à l’échelle et la réplication.
L’écriture ou la lecture d’un sujet fait toujours référence à une partition. Chaque partition est triée par son décalage. Si vous écrivez un message sur un sujet, vous avez la possibilité de spécifier une clé.
Le hachage de cette clé garantit que tous les messages avec la même clé se retrouvent dans la même partition. Le respect de l’ordre des messages entrants est garanti au sein d’une partition.
Interfaces Kafka
Globalement, Kafka propose ces quatre interfaces principales (API – Application Programming Interfaces) :
- API de producteur
- API consommateur
- API de flux
- ConnectAPI
L’API Producer permet aux applications d’écrire des données ou des messages dans un cluster Kafka. Les données d’un cluster Kafka peuvent être lues via l’API Consumer. Les API Producteur et Consommateur utilisent le protocole de message Kafka. C’est un protocole binaire. En principe, développer des clients producteurs et consommateurs est possible dans n’importe quel langage de programmation.
L’API Streams est une bibliothèque Java. Il peut traiter les flux de données de manière dynamique et tolérante aux pannes. Le filtrage, le regroupement et l’affectation des données sont possibles via les opérateurs fournis. De plus, vous pouvez intégrer vos opérateurs dans l’API.
L’API Streams prend en charge les tables, les jointures et les fenêtres horaires. Le stockage fiable des états de l’application est assuré par la journalisation de tous les changements d’état dans Kafka Topics. En cas d’échec, l’état de l’application peut être restauré en lisant les changements d’état à partir de la rubrique.
L’API Kafka Connect fournit les interfaces pour charger et exporter des données depuis ou vers des systèmes tiers. Il est basé sur les API Producteur et Consommateur.
Des connecteurs spéciaux gèrent la communication avec des systèmes tiers. De nombreux connecteurs commerciaux ou gratuits connectent des systèmes tiers de différents fabricants à Kafka.
Caractéristiques de Kafka

Kafka est un outil précieux pour les organisations qui cherchent à créer des systèmes de données en temps réel. Certaines de ses principales caractéristiques sont :
Haut débit
Kafka est un système distribué qui peut fonctionner sur plusieurs machines et est conçu pour gérer un débit de données élevé, ce qui en fait un choix idéal pour gérer de grandes quantités de données en temps réel.
Durabilité et faible latence
Kafka stocke toutes les données publiées, ce qui signifie que même si un consommateur est hors ligne, il peut toujours consommer les données une fois qu’il revient en ligne. De plus, Kafka est conçu pour avoir une faible latence, de sorte qu’il peut traiter les données rapidement et en temps réel.
Haute évolutivité
Kafka peut gérer une quantité croissante de données en temps réel avec peu ou pas de dégradation des performances, ce qui le rend adapté à une utilisation dans des applications de traitement de données à grande échelle et à haut débit.
Tolérance aux pannes
La tolérance aux pannes est également intégrée à la conception de Kafka car elle réplique les données sur plusieurs nœuds, donc si un nœud tombe en panne, il est toujours disponible sur les autres nœuds. Kafka garantit que les données sont toujours disponibles, même en cas de panne.
Modèle de publication-abonnement
Dans Kafka, les producteurs écrivent des données sur des sujets et les consommateurs lisent à partir de sujets. Cela permet un degré élevé de découplage entre les producteurs de données et les consommateurs, ce qui en fait une excellente option pour créer des architectures pilotées par les événements.
API simplifiée
Kafka fournit une API simple et facile à utiliser pour produire et consommer des données, la rendant accessible à un large éventail de développeurs.
Compression
Kafka prend en charge la compression des données, ce qui peut aider à réduire la quantité d’espace de stockage requise et à augmenter la vitesse de transfert des données.
Traitement de flux en temps réel
Kafka peut être utilisé pour le traitement de flux en temps réel, permettant aux organisations de traiter les données en temps réel au fur et à mesure qu’elles sont générées.
Utilise des cas de Kafka
Kafka offre un large éventail d’utilisations possibles. Les domaines d’application typiques sont :
Suivi de l’activité du site Web en temps réel
Kafka peut collecter, traiter et analyser les données d’activité du site Web en temps réel, permettant aux entreprises d’obtenir des informations et de prendre des décisions en fonction du comportement des utilisateurs.
Analyse des données financières en temps réel
Kafka vous permet de traiter et d’analyser les données financières en temps réel, permettant une identification plus rapide des tendances et des ruptures potentielles.
Surveillance des applications distribuées
Kafka peut collecter et traiter les données des journaux à partir d’applications distribuées, permettant aux organisations de surveiller leurs performances et d’identifier et de résoudre rapidement les problèmes.
Agrégation de fichiers journaux provenant de différentes sources
Kafka peut les agréger à partir de différentes sources et les rendre disponibles dans un emplacement centralisé pour analyse et surveillance.
Synchronisation des données dans les systèmes distribués
Kafka vous permet de synchroniser les données sur plusieurs systèmes, garantissant que tous les systèmes disposent des mêmes informations et peuvent fonctionner ensemble efficacement. C’est pourquoi il est utilisé par les magasins de détail comme Walmart.
Un autre domaine d’application important pour Kafka est l’apprentissage automatique. Kafka prend en charge l’apprentissage automatique, entre autres :
Formation de modèles en temps réel
Apache Kafka peut diffuser des données en temps réel pour former des modèles d’apprentissage automatique, permettant des prédictions plus précises et à jour.
Dérivation de modèles analytiques en temps réel
Kafka peut traiter et analyser des données pour dériver des modèles analytiques, fournissant des informations et des prévisions qui peuvent être utilisées pour prendre des décisions et agir.
Des exemples d’applications d’apprentissage automatique sont la détection des fraudes en reliant les informations de paiement en temps réel aux données et modèles historiques, la vente croisée via des offres personnalisées et spécifiques au client basées sur des données actuelles, historiques ou basées sur la localisation, ou la maintenance prédictive via la machine l’analyse des données.
Ressources d’apprentissage Kafka
Maintenant que nous avons parlé de ce qu’est Kafka et de ses cas d’utilisation, voici quelques ressources qui vous aideront à apprendre et à utiliser Kafka dans le monde réel :
#1. Série Apache Kafka – Apprenez Apache Kafka pour les débutants v3
Apprendre Apache Kafka pour les débutants est un cours d’introduction proposé par Stéphane Maarek sur Udemy. Le cours vise à fournir une introduction complète à Kafka aux personnes qui découvrent cette technologie mais qui ont une compréhension préalable de Java et Linux CLI.
Il couvre tous les concepts fondamentaux et fournit des exemples pratiques ainsi qu’un projet concret qui vous aide à mieux comprendre le fonctionnement de Kafka.

#2. Série Apache Kafka – Flux Kafka
Kafka Streams pour le traitement des données est un autre cours proposé par Stéphane Maarek visant à fournir une compréhension approfondie de Kafka Streams.
Le cours couvre des sujets tels que l’architecture Kafka Streams, l’API Kafka Streams, Kafka Streams, Kafka Connect, Kafka Streams et KSQL, et inclut des cas d’utilisation réels et comment les mettre en œuvre à l’aide de Kafka Streams. Le cours est conçu pour être accessible à ceux qui ont une expérience préalable avec Kafka.

#3. Apache Kafka pour débutant absolu
Kafka pour les débutants absolus est un cours adapté aux débutants qui couvre les bases de Kafka, y compris son architecture, ses concepts de base et ses fonctionnalités. Il couvre également la mise en place et la configuration d’un cluster Kafka, la production et la consommation de messages, et un micro projet.

#4. Le guide pratique complet d’Apache Kafka
Kafka guide pratique vise à fournir une expérience pratique de travail avec Kafka. Il couvre également les concepts fondamentaux de Kafka et un guide pratique sur la création de clusters, plusieurs courtiers et l’écriture de producteurs et de consoles personnalisés. Ce cours ne nécessite aucun prérequis.

#5. Créer des applications de streaming de données avec Apache Kafka
Création d’applications de streaming de données avec Apache Kafka est un guide destiné aux développeurs et aux architectes qui souhaitent apprendre à créer des applications de streaming de données à l’aide d’Apache Kafka.
Le livre couvre les concepts clés et l’architecture de Kafka et explique comment utiliser Kafka pour créer des pipelines de données en temps réel et des applications de streaming.
Il couvre des sujets tels que la configuration d’un cluster Kafka, l’envoi et la réception de messages et l’intégration de Kafka avec d’autres systèmes et outils. En outre, le livre fournit les meilleures pratiques pour aider les lecteurs à créer des applications de streaming de données hautes performances et évolutives.
#6. Guide de démarrage rapide d’Apache Kafka
Le guide de démarrage rapide de Kafka couvre les bases de Kafka, y compris son architecture, ses concepts clés et ses opérations de base. Il fournit également des instructions pas à pas pour configurer un cluster Kafka simple et l’utiliser pour envoyer et recevoir des messages.
En outre, le guide fournit un aperçu des fonctionnalités plus avancées telles que la réplication, le partitionnement et la tolérance aux pannes. Ce guide est destiné aux développeurs, architectes et ingénieurs de données qui découvrent Kafka et souhaitent se familiariser rapidement avec la plate-forme.
Conclusion
Apache Kafka est une plateforme de streaming distribuée qui crée des pipelines de données en temps réel et des applications de streaming. Kafka joue un rôle clé dans les systèmes de Big Data en fournissant un moyen rapide, fiable et évolutif de collecter et de traiter de grandes quantités de données en temps réel.
Il permet aux entreprises d’obtenir des informations, de prendre des décisions basées sur les données et d’améliorer leurs opérations et leurs performances globales.
Vous pouvez également explorer le traitement des données avec Kafka et Spark.
Si quiere puede hacernos una donación por el trabajo que hacemos, lo apreciaremos mucho.
Direcciones de Billetera:
- BTC: 14xsuQRtT3Abek4zgDWZxJXs9VRdwxyPUS
- USDT: TQmV9FyrcpeaZMro3M1yeEHnNjv7xKZDNe
- BNB: 0x2fdb9034507b6d505d351a6f59d877040d0edb0f
- DOGE: D5SZesmFQGYVkE5trYYLF8hNPBgXgYcmrx
También puede seguirnos en nuestras Redes sociales para mantenerse al tanto de los últimos post de la web:
- Telegram
Disclaimer: En Cryptoshitcompra.com no nos hacemos responsables de ninguna inversión de ningún visitante, nosotros simplemente damos información sobre Tokens, juegos NFT y criptomonedas, no recomendamos inversiones