
The processing of big data is one of the most complex procedures that organizations face. The process becomes more complicated when you have a large volume of real-time data.

In this post, we will discover what big data processing is, how it is done, and explore Apache Kafka and Spark – the two of the most famous data processing tools!
What is Data Processing? How is it done?
Data processing is defined as any operation or set of operations, whether or not carried out using an automated process. It can be thought of as the collection, ordering, and organization of information according to a logical and appropriate disposition for interpretation.

When a user accesses a database and gets results for their search, it’s the data processing that’s getting them the results they need. The information extracted as a search result is the result of data processing. That is why information technology has the focus of its existence centered on data processing.
Traditional data processing was carried out using simple software. However, with the emergence of Big Data, things have changed. Big Data refers to information whose volume can be over a hundred terabytes and petabytes.
Moreover, this information is regularly updated. Examples include data coming from contact centers, social media, stock exchange trading data, etc. Such data is sometimes also called data stream- a constant, uncontrolled stream of data. Its main characteristic is that the data has no defined limits, so it is impossible to say when the stream starts or ends.
Data is processed as it arrives at the destination. Some authors call it real-time or online processing. A different approach is block, batch, or offline processing, in which blocks of data are processed in time windows of hours or days. Often the batch is a process that runs at night, consolidating that day’s data. There are cases of time windows of a week or even a month generating outdated reports.
Given that the best Big Data processing platforms via streaming are open sources such as Kafka and Spark, these platforms allow the use of other different and complementary ones. This means that being open source, they evolve faster and use more tools. In this way, data streams are received from other places at a variable rate and without any interruptions.
Now, we will look at two of the most widely known data processing tool and compare them:
Apache Kafka
Apache Kafka is a messaging system that creates streaming applications with a continuous data flow. Originally created by LinkedIn, Kafka is log-based; a log is a basic form of storage because each new information is added to the end of the file.
 cryptoshitcompra.com/wp-content/uploads/2022/09/Start-Data-Processing-with-Kafka-and-Spark.jpg» alt=»YouTube video» width=»480″ height=»360″ data-pin-nopin=»true»/>
cryptoshitcompra.com/wp-content/uploads/2022/09/Start-Data-Processing-with-Kafka-and-Spark.jpg» alt=»YouTube video» width=»480″ height=»360″ data-pin-nopin=»true»/>Kafka is one of the best solutions for big data because its main characteristic is its high throughput. With Apache Kafka, it is even possible to transform batch processing in real-time,
Apache Kafka is a publish-subscribe messaging system in which an application publishes and an application that subscribes receives messages. The time between publishing and receiving the message can be milliseconds, so a Kafka solution has low latency.
Working of Kafka
Apache Kafka’s architecture comprises producers, consumers, and the cluster itself. The producer is any application that publishes messages to the cluster. The consumer is any application that receives messages from Kafka. The Kafka cluster is a set of nodes that function as a single instance of the messaging service.
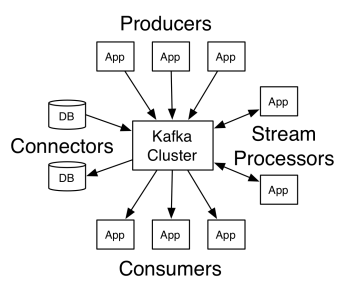
A Kafka cluster is made up of several brokers. A broker is a Kafka server that receives messages from producers and writes them to disk. Each broker manages a list of topics, and each topic is divided into several partitions.
After receiving the messages, the broker sends them to the registered consumers for each topic.
Apache Kafka settings are managed by Apache Zookeeper, which stores cluster metadata such as partition location, list of names, list of topics, and available nodes. Thus, Zookeeper maintains synchronization between the different elements of the cluster.
Zookeeper is important because Kafka is a distributed system; that is, the writing and reading are done by several clients simultaneously. When there is a failure, the Zookeeper elects a replacement and recovers the operation.
Use Cases
Kafka became popular, especially for its use as a messaging tool, but its versatility goes beyond that, and it can be used in a variety of scenarios, as in the examples below.
Messaging
Asynchronous form of communication that decouples the parties that communicate. In this model, one party sends the data as a message to Kafka, so another application later consumes it.
Activity tracking
Enables you to store and process data tracking a user’s interaction with a website, such as page views, clicks, data entry, etc.; this type of activity usually generates a large volume of data.
Metrics
Involves aggregating data and statistics from multiple sources to generate a centralized report.
Log aggregation
Centrally aggregates and stores log files originating from other systems.
Stream Processing
Processing of data pipelines consists of multiple stages, where raw data is consumed from topics and aggregated, enriched, or transformed into other topics.
To support these features, the platform essentially provides three APIs:
- Streams API: It acts as a stream processor that consumes data from one topic, transforms it, and writes it to another.
- Connectors API: It allows connecting topics to existing systems, such as relational databases.
- Producer and consumer APIs: It allows applications to publish and consume Kafka data.
Pros
Replicated, Partitioned, and Ordered
Messages in Kafka are replicated across partitions across cluster nodes in the order they arrive to ensure security and speed of delivery.
Data Transformation
With Apache Kafka, it is even possible to transform batch processing in real-time using batch ETL streams API.
Sequential disk access
Apache Kafka persists the message on disk and not in memory, as it is supposed to be faster. In fact, memory access is faster in most situations, especially when considering accessing data that is at random locations in memory. However, Kafka does sequential access, and in this case, the disk is more efficient.
Apache Spark
Apache Spark is a big data computing engine and set of libraries for processing parallel data across clusters. Spark is an evolution of Hadoop and the Map-Reduce programming paradigm. It can be 100x times faster thanks to its efficient use of memory that does not persist data on disks while processing.

Spark is organized at three levels:
- Low-Level APIs: This level contains the basic functionality to run jobs and other functionality required by the other components. Other important functions of this layer are the management of security, network, scheduling, and logical access to file systems HDFS, GlusterFS, Amazon S3, and others.
- Structured APIs: The Structured API level deals with data manipulation through DataSets or DataFrames, which can be read in formats such as Hive, Parquet, JSON, and others. Using SparkSQL (API that allows us to write queries in SQL), we can manipulate the data the way we want.
- High Level: At the highest level, we have the Spark ecosystem with various libraries, including Spark Streaming, Spark MLlib, and Spark GraphX. They are responsible for taking care of streaming ingestion and the surrounding processes, such as crash recovery, creating and validating classic machine learning models, and dealing with graphs and algorithms.
Working of Spark
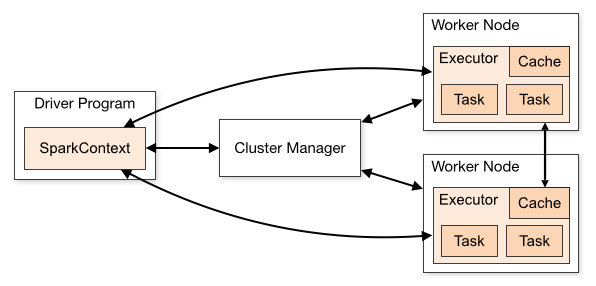
The architecture of a Spark application consists of three main parts:
Driver Program: It is responsible for orchestrating the execution of data processing.
Cluster Manager: It is the component responsible for managing the different machines in a cluster. Only needed if Spark runs distributed.
Workers Nodes: These are the machines that perform the tasks of a program. If Spark is run locally on your machine, it will play a Driver Program and a Workes role. This way of running Spark is called Standalone.
Spark code can be written in a number of different languages. The Spark console, called Spark Shell, is interactive for learning and exploring data.
The so-called Spark application consists of one or more Jobs, enabling the support of large-scale data processing.
When we talk about execution, Spark has two modes:
- Client: The driver runs directly on the client, which does not go through the Resource Manager.
- Cluster: Driver running on the Application Master through the Resource Manager (In Cluster mode, if the client disconnects, the application will continue running).
It’s necessary to use Spark correctly so that the linked services, such as the Resource Manager, can identify the need for each execution, providing the best performance. So it’s up to the developer to know the best way to run their Spark jobs, structuring the call made, and for this, you can structure and configure the executors Spark the way you want.
Spark jobs primarily use memory, so it is common to adjust Spark configuration values for work node executors. Depending on the Spark workload, it is possible to determine that a certain non-standard Spark configuration provides more optimal executions. To this end, comparison tests between the various available configuration options and the default Spark configuration itself can be performed.
Uses Cases
Apache Spark helps in processing huge amounts of data, whether real-time or archived, structured or unstructured. Following are some of its popular use cases.
Data Enrichment
Often companies use a combination of historical customer data with real-time behavioral data. Spark can help build a continuous ETL pipeline to convert unstructured event data into structured data.
Trigger Event Detection
Spark Streaming allows rapid detection and response to some rare or suspicious behavior that could indicate a potential problem or fraud.
Complex Session Data Analysis
Using Spark Streaming, events related to the user’s session, such as their activities after logging into the application, can be grouped and analyzed. This information can also be used continuously to update machine learning models.
Pros
Iterative processing
If the task is to process data repeately, Spark’s resilient Distributed Datasets (RDDs) allow multiple in-memory map operations without having to write interim results to disk.
Graphic processing
Spark’s computational model with GraphX API is excellent for iterative calculations typical of graphics processing.
Machine learning
Spark has MLlib — a built-in machine learning library that has ready-made algorithms that also run in memory.
Kafka vs. Spark
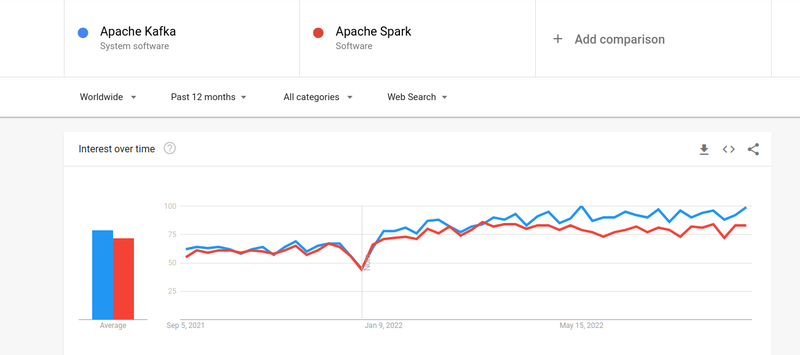
Even though the interest of people in both Kafka and Spark has been almost similar, there do exist some major differences between the two; let’s have a look.
#1. Data processing
Kafka is a real-time data streaming and storage tool responsible for transferring data between applications, but it is not enough to build a complete solution. Therefore, other tools are needed for tasks that Kafka does not, such as Spark. Spark, on the other hand, is a batch-first data processing platform that draws data from Kafka topics and transforms it into combined schemas.
#2. Memory Management
Spark uses Robust Distributed Datasets (RDD) for memory management. Instead of trying to process huge data sets, it distributes them over multiple nodes in a cluster. In contrast, Kafka uses sequential access similar to HDFS and stores data in a buffer memory.
#3. ETL Transformation
Both Spark and Kafka support the ETL transformation process, which copies records from one database to another, usually from a transactional basis (OLTP) to an analytical basis (OLAP). However, unlike Spark, which comes with a built-in ability for ETL process, Kafka relies on Streams API to support it.
#4. Data Persistence

Spark’s use of RRD allows you to store the data in multiple locations for later use, whereas in Kafka, you have to define dataset objects in configuration to persist data.
#5. Difficulty
Spark is a complete solution and easier to learn due to its support for various high-level programming languages. Kafka depends on a number of different APIs and third-party modules, which can make it difficult to work with.
#6. Recovery
Both Spark and Kafka provide recovery options. Spark uses RRD, which allows it to save data continuously, and if there’s a cluster failure, it can be recovered.

Kafka continuously replicates data inside the cluster and replication across brokers, which allows you to move on to the different brokers if there is a failure.
Similarities between Spark and Kafka
| Apache Spark | Apache Kafka |
| OpenSource | OpenSource |
| Build Data Streaming Application | Build Data Streaming Application |
| Supports Stateful Processing | Supports Stateful Processing |
| Supports SQL | Supports SQL |
Final Words
Kafka and Spark are both open-source tools written in Scala and Java, which allow you to build real-time data streaming applications. They have several things in common, including stateful processing, support for SQL, and ETL. Kafka and Spark can also be used as complementary tools to help solve the problem of the complexity of transferring data between applications.
Si quiere puede hacernos una donación por el trabajo que hacemos, lo apreciaremos mucho.
Direcciones de Billetera:
- BTC: 14xsuQRtT3Abek4zgDWZxJXs9VRdwxyPUS
- USDT: TQmV9FyrcpeaZMro3M1yeEHnNjv7xKZDNe
- BNB: 0x2fdb9034507b6d505d351a6f59d877040d0edb0f
- DOGE: D5SZesmFQGYVkE5trYYLF8hNPBgXgYcmrx
También puede seguirnos en nuestras Redes sociales para mantenerse al tanto de los últimos post de la web:
- Telegram
Disclaimer: En Cryptoshitcompra.com no nos hacemos responsables de ninguna inversión de ningún visitante, nosotros simplemente damos información sobre Tokens, juegos NFT y criptomonedas, no recomendamos inversiones